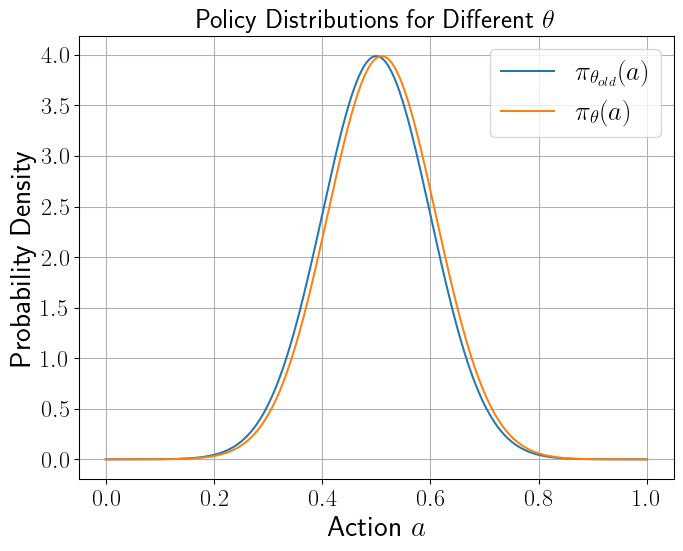
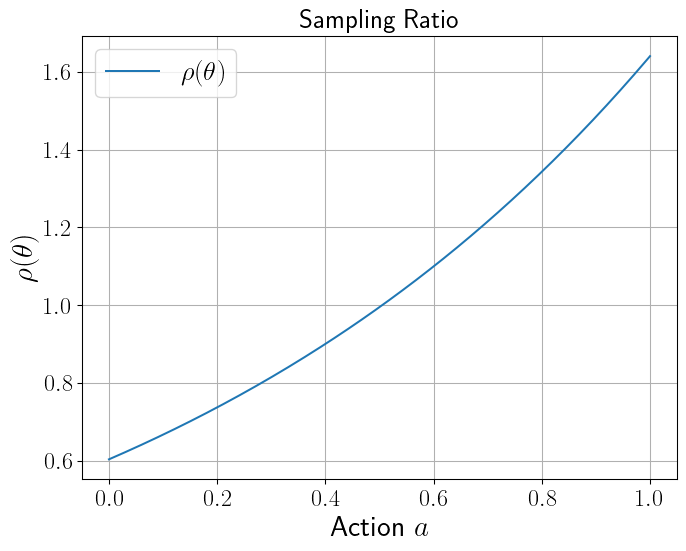
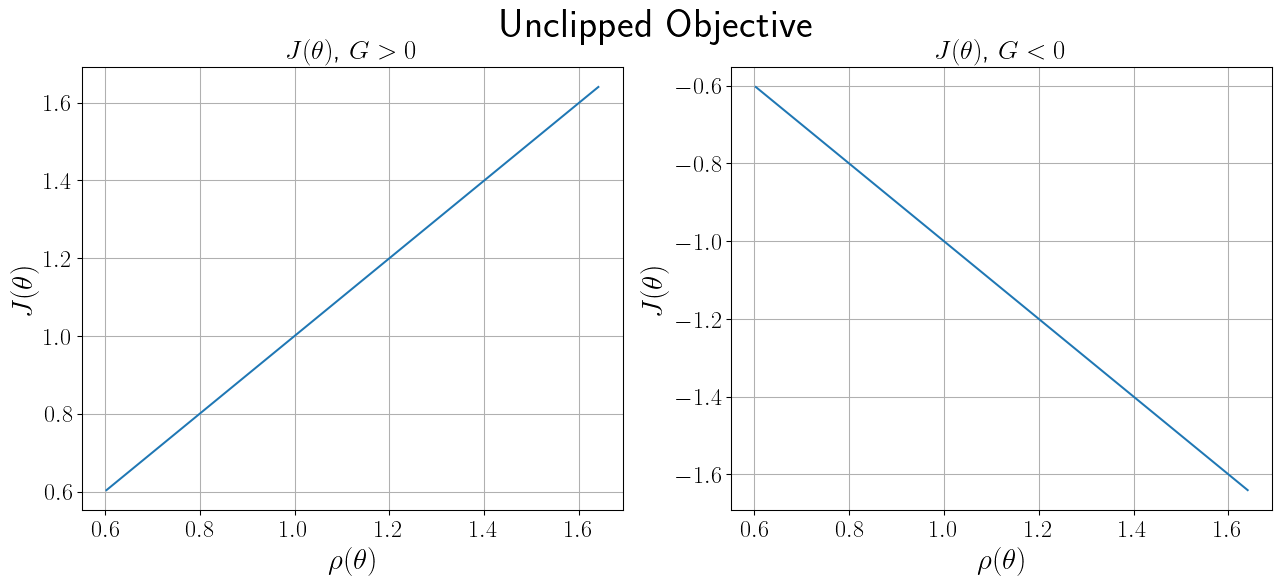
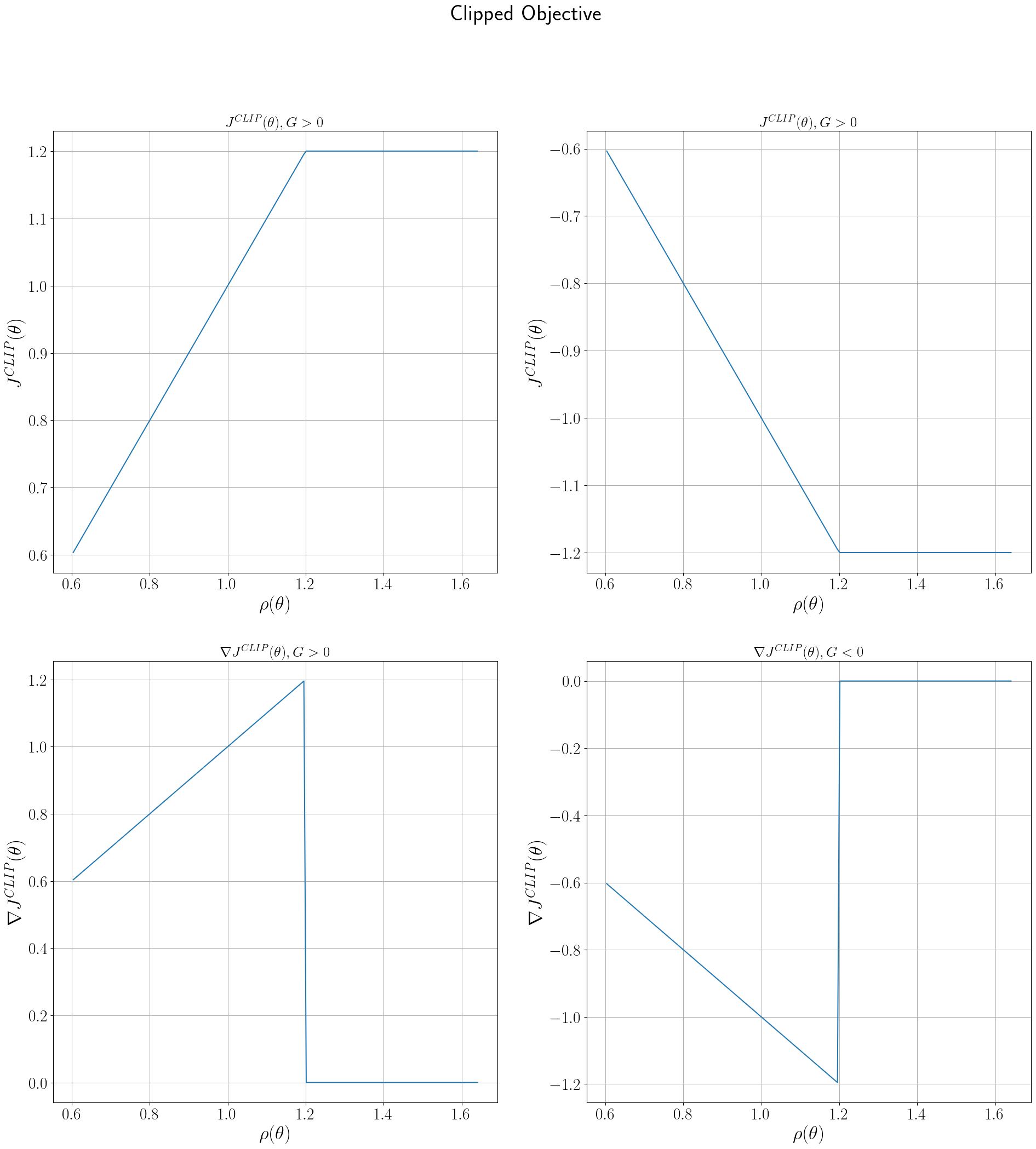
Before
obs_buffer shape: (2, 4, 3)
obs_buffer contents:
array([[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]])
obs_buffer_alt shape: (4, 2, 3)
obs_buffer_alt contents:
array([[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]])
After
obs_buffer shape: (2, 4, 3)
obs_buffer contents:
array([[[ 1.76405235, 0.40015721, 0.97873798],
[ 2.2408932 , 1.86755799, -0.97727788],
[ 0.95008842, -0.15135721, -0.10321885],
[ 0.4105985 , 0.14404357, 1.45427351]],
[[ 0. , 0. , 0. ],
[ 0. , 0. , 0. ],
[ 0. , 0. , 0. ],
[ 0. , 0. , 0. ]]])
obs_buffer_alt shape: (4, 2, 3)
obs_buffer_alt contents:
array([[[ 1.76405235, 0.40015721, 0.97873798],
[ 0. , 0. , 0. ]],
[[ 2.2408932 , 1.86755799, -0.97727788],
[ 0. , 0. , 0. ]],
[[ 0.95008842, -0.15135721, -0.10321885],
[ 0. , 0. , 0. ]],
[[ 0.4105985 , 0.14404357, 1.45427351],
[ 0. , 0. , 0. ]]])